
Alright, so today I’m gonna walk you through my little experiment with navone prediction. It’s not rocket science, but I figured I’d share what I did and what I learned.
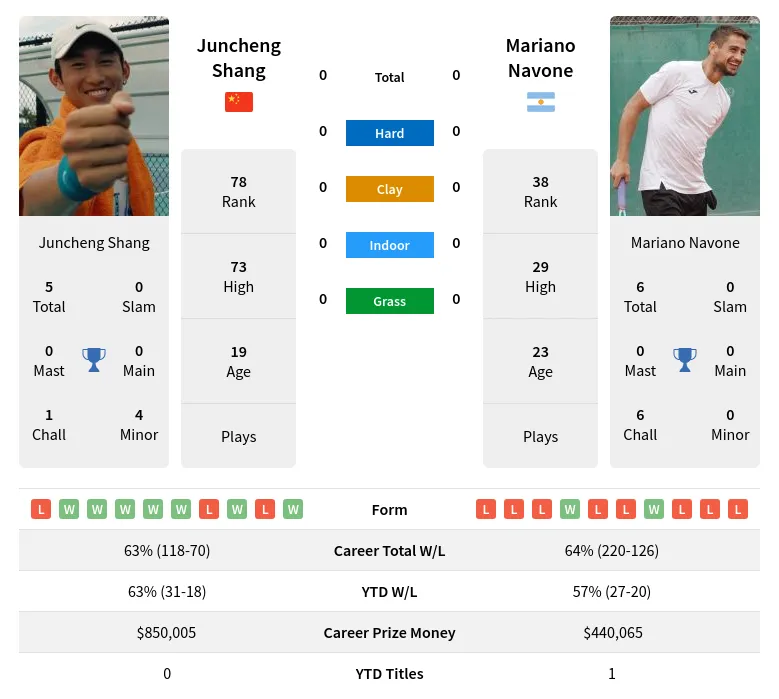
It all started when I was messing around with some navigation data. I thought, “Hey, wouldn’t it be cool if I could predict where someone’s gonna go next based on their past movements?” So, I dove in.
First things first, I needed data. I scraped together some location data from my own phone (with permission, of course! haha). It was basically a bunch of latitude and longitude points with timestamps. Nothing fancy.
Next up, I cleaned the data. This was a pain. There were missing values, weird outliers, you name it. I used pandas (Python, gotta love it) to handle most of it. Filled in the gaps with some basic interpolation, tossed out the crazy outliers that were clearly GPS glitches. Tedious but necessary.
Okay, now for the “prediction” part. I kept it simple. I decided to use a Markov model. Basically, I looked at the probability of transitioning from one location to another. I broke down my entire dataset into sequences of locations, and for each location, I counted how many times I transitioned to every other location in the set.
Then I built a transition matrix. Each cell (i, j) in the matrix represented the probability of moving from location i to location j. Just a simple count-based probability, normalized so each row sums to one.
To make a prediction, I just looked at my current location and then picked the next location with the highest probability according to my transition matrix. Super basic, I know, but it was a starting point.
I wrote a little script to test it out. Gave it a starting location, and it spat out the most likely next location. And you know what? It actually worked… sometimes! Like, if I was at home, it would often correctly predict that I’d go to the grocery store or work. Not always, of course. Sometimes it would suggest I teleport to some random place I visited once six months ago.
So, what did I learn? Well, first, data quality is king. The cleaner your data, the better your predictions. Second, a Markov model is a super simple way to get started, but it has its limitations. It doesn’t account for time of day, day of the week, or any other contextual information that would probably improve accuracy. Third, navone prediction is harder than it looks!
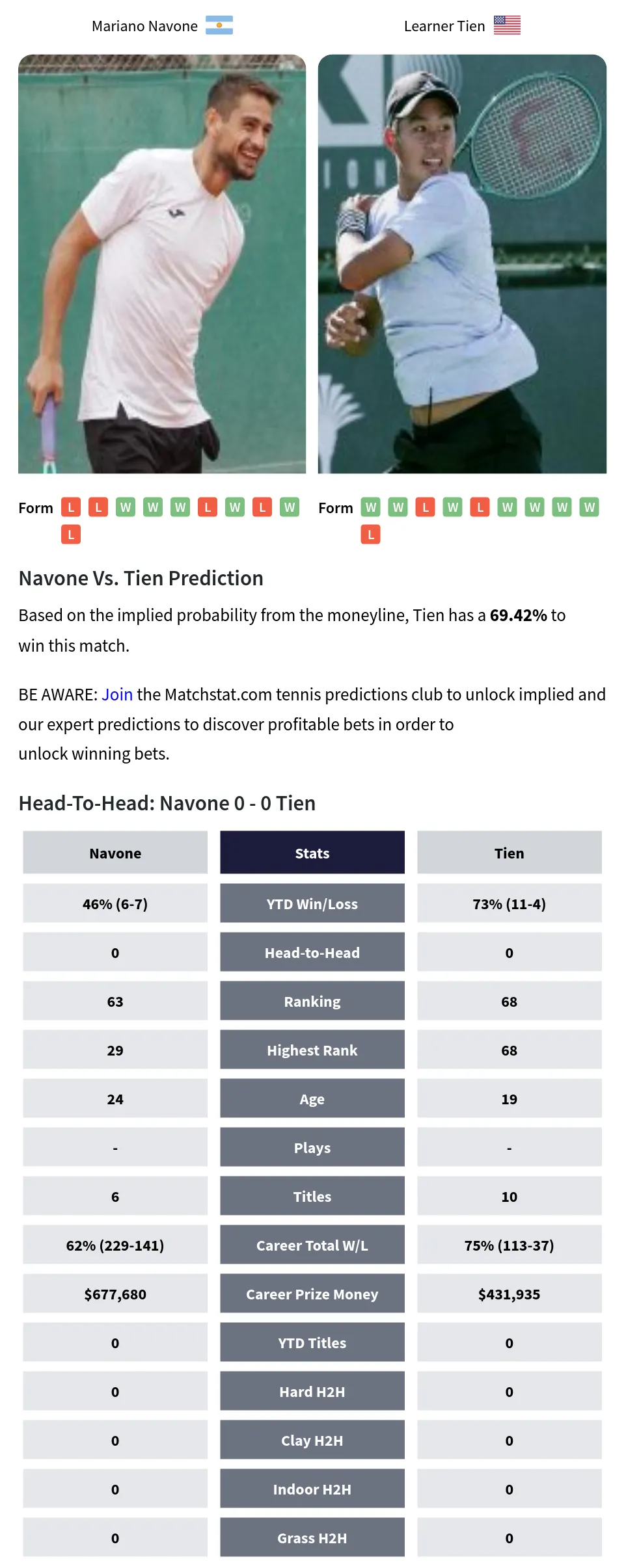
This was just a fun little project, but it got me thinking about all the cool stuff you could do with more sophisticated models and more data. Maybe next time I’ll try throwing in some machine learning or something. Who knows?



{kind=link}